
Most agent frameworks today assume a desktop. One user, one machine, one process. The agent runs while the laptop is open, writes to a local filesystem, holds API keys in environment variables, and dies when the terminal closes. When something breaks, the user retries. When the agent needs a package, pip install drops it into the user's Python. State, secrets, and lifecycle all sit inside one trusted boundary.
Cloud agent infrastructure has none of those luxuries.
The agent runs on a sandbox that boots fresh, on hardware shared with strangers, triggered by callers the user never meets: a schedule, an HTTP request, another agent. The user is usually asleep when the run happens. The code inside the sandbox may be adversarial. The filesystem has to survive deployments. Credentials cannot live where the agent lives. Every guarantee the desktop gives you for free — persistence, identity, network trust, retry — has to be rebuilt as an explicit system.
We spent the last few months tightening that layer at CREAO. Two lessons came out of it. If you have ever shipped a desktop agent and wondered what changes when it moves to the cloud, this is what changes.
Lesson 1: Separate What Changes Slowly from What Changes Fast

On a desktop, the user's environment and the agent's runtime are the same thing, updated on the same cadence, by the same person. In the cloud, they are not.
An agent app accumulates state on the platform's side. A stock analyst installs matplotlib, downloads market data, writes charting scripts. That environment is the agent's muscle memory. We freeze it into a sandbox snapshot the moment the user is happy with it, and we hold that snapshot frozen until the user edits the environment again. Every run boots from the same image. Same packages, same files, same versions. Monday's run behaves like Friday's, because nothing underneath has moved.
This is the property that desktop frameworks cannot give you for free. A pip install six months ago resolves to different versions today. A cloud snapshot resolves to the same bytes forever. Reproducibility is something the platform owes the user, and a frozen snapshot is the cheapest way to deliver it.
Then the coupling problem shows up.
The same image that freezes the user's environment also contains the runner code — the small harness library developed by us that manages the agent on each run. The user wants their environment to stay still. We want our runner to ship many times a day. One artifact, two opposite requirements.
Our first fix was blunt. On boot, check whether the runner inside the snapshot matches the version we just deployed. If it doesn't, throw the snapshot away and boot from a clean template. It worked, and nobody complained. The damage only hit the first run after a deployment.
Unattended runs killed that cover. A cron job at 9am Monday should not lose its environment because we deployed at 8:55. The contract we were quietly violating — "your environment is frozen until you change it"
The fix took us longer than it should have to see. The user's environment and the runner code change at completely different rates. The user edits their agent when they choose to. We deploy the platform many times a day. Treating them as one artifact forced a choice on every deployment: keep stale runner code, or destroy the frozen environment the user explicitly asked us to preserve.
The model we landed on borrows from how operating systems handle updates. The kernel changes. Your home directory does not. You do not wipe the disk to install a security patch.
We drew the same boundary. The sandbox boots from the user's frozen snapshot, untouched. Then we hot-swap only the runner. The sequence:
Stage the new runner in a temp directory inside the sandbox.
Validate it with node --check so any syntax error is caught before we touch anything live.
Atomically swap it in: unlock the immutable flag on the old runner, copy the new one over, re-lock with chattr +i, then hide the chattr binary itself so sandbox code cannot reverse the lock.
Purge V8's compile cache (/home/user/.cache/v8-compile-cache/*) so the new file actually loads instead of running stale bytecode.
If any step fails, kill the sandbox and retry with a fresh one. No half-upgraded state ever runs an agent.
The whole swap takes about 300 milliseconds. We re-snapshot after a successful run only when the runner code was swapped, baking the updated code into the user's image so the next run skips the swap entirely. Platform deployments never discard the user's state; they fold the new runner into it. The user's packages, files, and customizations carry forward unchanged.
If you take one thing from this lesson, it is the diagnostic question. For anything you persist in a cloud platform, ask: who controls the cadence of change on this artifact? If the user and the platform both own it, you will eventually pay for the coupling. Split the artifact along the ownership boundary and let each side update on its own clock.
Lesson 2: Keep Secrets Out of the Execution Boundary
This is the lesson that separates cloud agent infrastructure from everything else.
A desktop agent runs as the user. It uses the user's keys, on the user's machine, against the user's network. A cloud agent runs as nobody, on shared hardware, against the open internet, executing code an LLM wrote from a prompt that may have been adversarial. The security model has to assume the code inside the sandbox is already compromised, not hope against it.
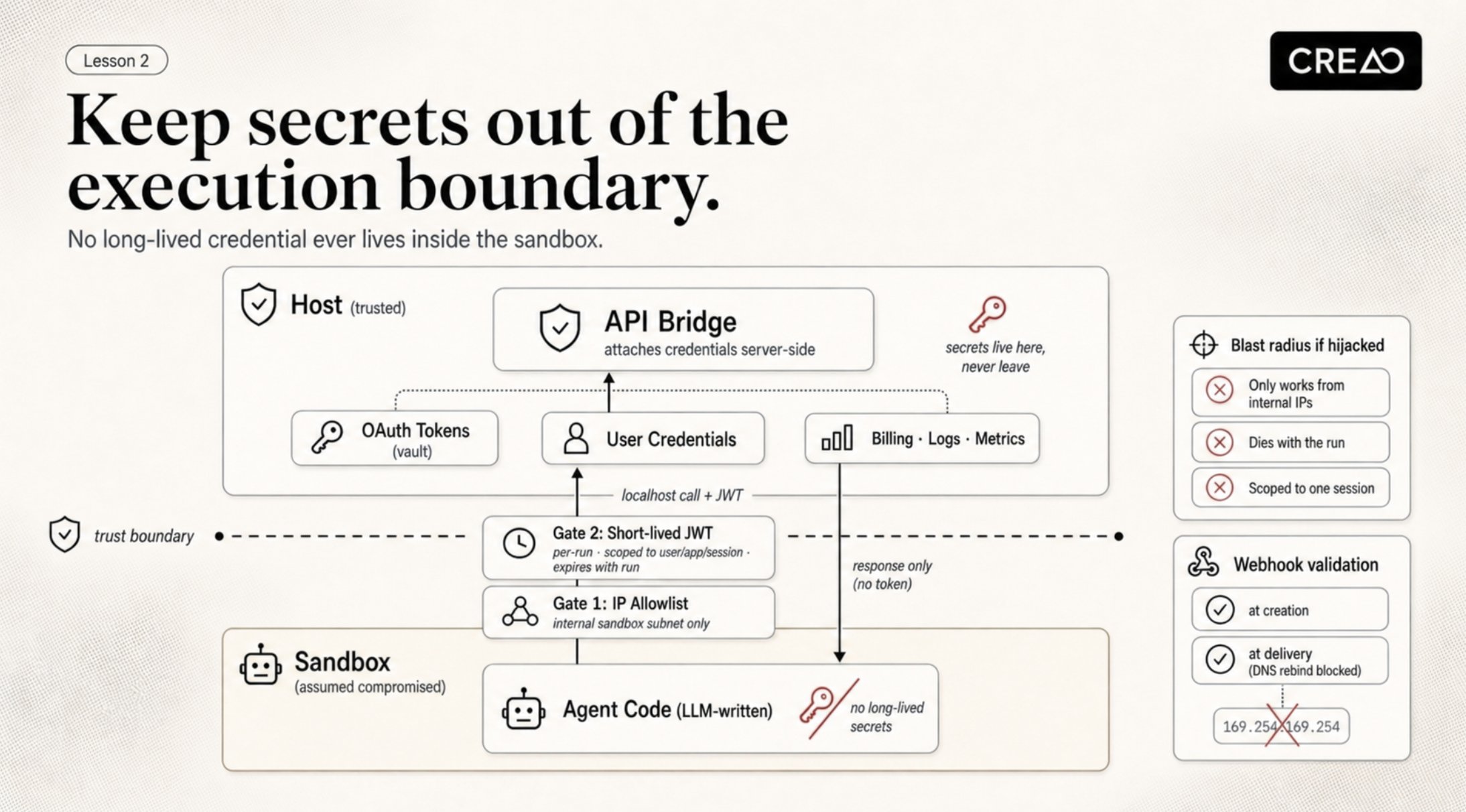
The rule we hold is simple. No long-lived credential ever lives inside the sandbox.
When an agent needs to call an authenticated service — Slack, GitHub, the user's own API — it does not hold the token. It sends a local HTTP request to an API bridge running outside the sandbox. The bridge attaches the OAuth token on the host side and forwards the call. The response comes back without the token ever entering the sandbox's memory or environment.
The interesting part is how the bridge knows the sandbox is allowed to ask. Two checks, layered on purpose.
First, IP allowlist. The bridge only accepts connections from the internal network range our sandbox hosts live on. A call from anywhere else — a developer laptop, a leaked URL, the public internet — is dropped at the network layer before any application code runs. This pins the bridge to one piece of physical infrastructure and makes it useless to anyone outside it.
Second, a short-lived JWT minted per run. When a sandbox boots, the platform signs a token scoped to that specific run: which user, which app, which session, with an expiry that covers the run window and nothing more. The sandbox presents it on every bridge call. The bridge verifies the signature, checks the expiry, and only then resolves the user's stored credentials and attaches them server-side. If a sandbox is hijacked, the attacker inherits a token that dies with the run and only authorizes calls scoped to that one session. There is no master credential to steal.
The same bridge carries billing deductions, logs, and metrics out, so it is the one interface that crosses the sandbox boundary in either direction. Everything else inside the sandbox is treated as compromised by default.
If a prompt injection convinces an agent to dump process.env to a webhook tomorrow, the attacker gets a short-lived JWT that only works from inside our network and expires with the run. That property is what lets us run untrusted user code on shared infrastructure without losing sleep.
The pattern underneath
Reliable, secure cloud agent infrastructure is not a novel system. It is a few properties held without exception:
State lives in the sandbox, frozen until the user changes it.
Code is hot-swappable, independent of state.
Credentials live host-side, never inside the agent.
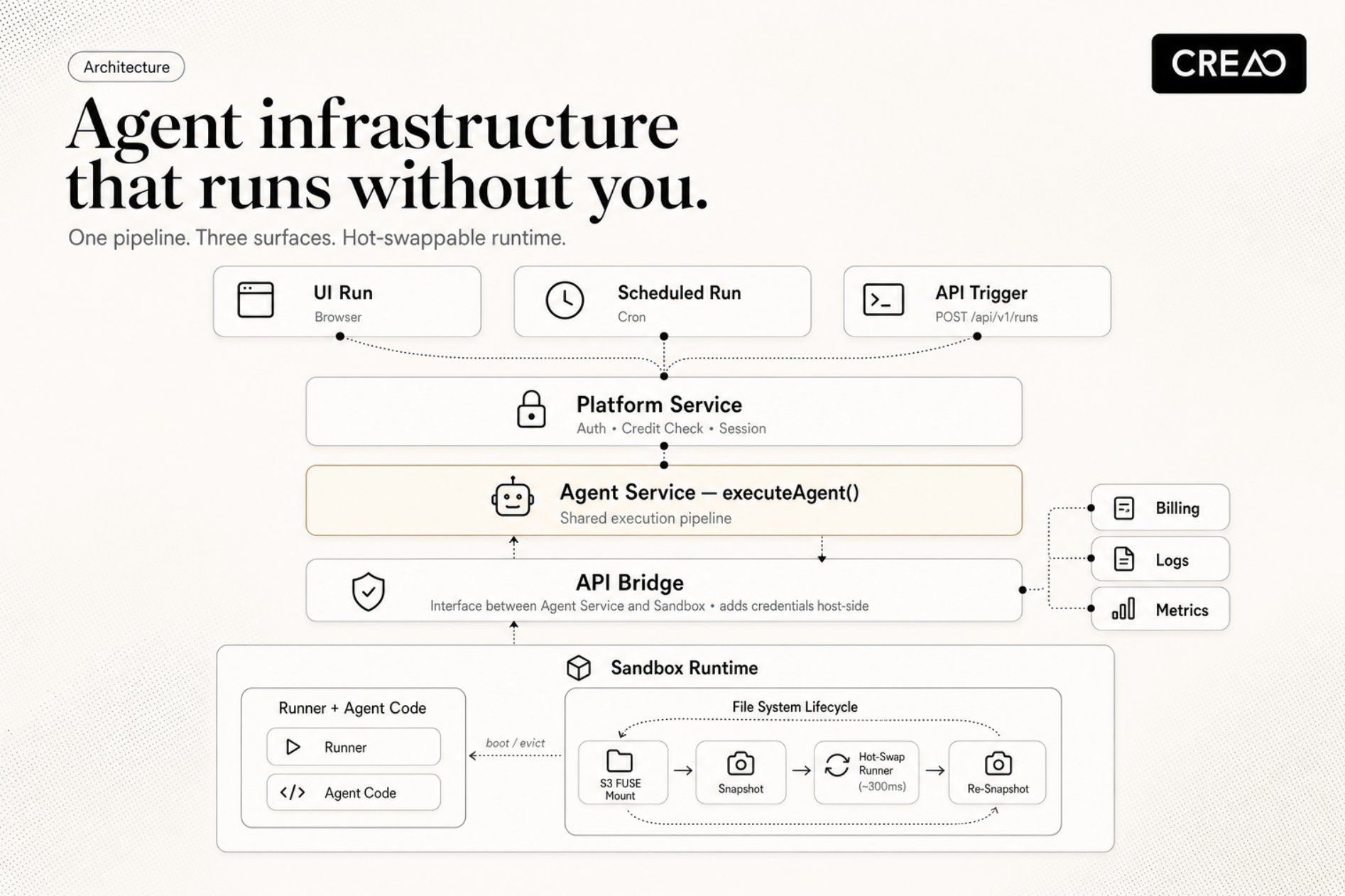
One execution pipeline serves every caller, whether the trigger is a human, a scheduler, or another piece of software.
That last property is the punchline of the whole design. One executeAgent function handles UI clicks, scheduled runs, and API calls. The billing system, the credit deduction logs, the observability signals — all identical regardless of whether a human clicked Run, a cron fired, or a script called the API. Adding a new trigger surface is a routing change, not an architecture change. The agent itself does not know or care who pulled the trigger.
That is what desktop frameworks cannot give you, and what makes the cloud version worth building. An agent on a laptop is bound to the laptop. An agent in the cloud is a function the rest of your stack can call. The user writes it once. The platform makes it survive deployments, run safely on shared hardware, and accept callers the user never anticipated.
An agent is a function with a natural language interface. Its implementation belongs to the user. Its trigger surface, its runtime, its security boundary belong to the platform. The discipline is to build the layers so each evolves on its own clock, and to spend the time finding the cracks between systems before someone else does.
That is what makes the next surface cheap to ship, and safe to ship.